
InfoSec Write-ups – Medium–
When putting together a SIEM, one of the first things that you need to decide on is the distributed architecture you’re going to choose. This means analyzing the resources available, as well as the needs of your SOC.
- Are you monitoring 100, 1000, or 10000 hosts?
- Do you have budget for commercial tools?
- How heterogeneous is your infrastructure?
- Are you just looking for security alerts, or do you also need persistent event logging for auditing purposes?
- What type of granularity are you looking to achieve?
- What response time do you wish to achieve? Do you need real time notifications?
- Do you have time to improve/tune your solution or do you need something working 100% ASAP?
These are some of the questions you need to ask yourself. In our particular case, we needed to set up a SIEM for a network of about 20K hosts. We didn’t have a budget for commercial tools or licenses. We needed persistent logging for auditing purposes. This included logging every command executed in our infrastructure, while monitoring for malicious ones. We also wanted low level granularity in order to write custom rules. Basically, we wanted a top-level SOC without spending money. But this is not possible.
The first thing that you should understand as a manager is that nothing comes for free. You might not have to pay for licenses if you choose to go open-source, but you will spend money putting together a team of people that can effectively:
1) Tune that open source solution to your needs without paying for support.
2) Contribute to that open source project if you want to give something back.
You either pay for talented employees, or you pay for close source + support. There’s not going around it. In my case, I was lucky to be working with a great team of security engineers and soc analysts who were able to work together to achieve all of the goals I detailed at the beginning.
You might be asking why is this relevant? Well, the architectural decisions we took might not fit your needs. You might be in need of something fast and which just does the job. You might not have a team of people who enjoy getting dirty. In that case, something like Splunk (https://www.splunk.com/) might suit you best. It will be expensive, especially if you have a sizable infrastructure to monitor, but it’ll be far easier to implement than what we did.
Having painted a picture of what our situation was at first, lets move forward. Looking into common SIEM architectures, the most common open source one involved ELK + something like Elastalert. I have talked about how to use ELK for logging purposes in my previous writeup.
This architecture usually has some kind of log/event forwarded (something like filebeat) running on each monitored host, which sends data to a Logstash ingestor, who parses it, enriches it, and sends it to a non-relational database (in this case Elastic) which can then be queried and visualized through dashboards (Kibana). It’ll look something like this.
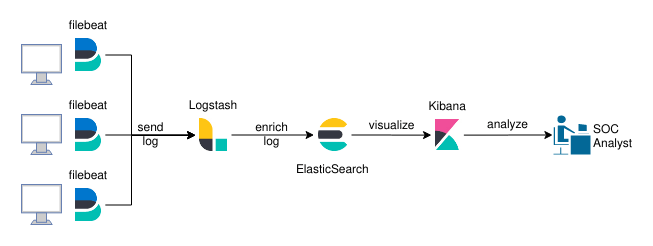
However, this design has an evident flaw. Its 100% manual work. The SOC analyst has to manually query and analyze the data to detect threads. You should try to automate every process as much as possible.
There’s also another issue with this. You’re not leaving a record of any finding/relevant event. At least not automatically.
To solve these two issues, you’ll need to add some sort of alert/notification system that persist information. This can be achieved with Elastalert (https://github.com/Yelp/elastalert). This is a python developed framework which queries Elasticsearch and notifies you when an alert has triggered.
We choose two notifications methods. The first was through a Slack channel for more urgent alerts. The second was through an inbox to leave a record.
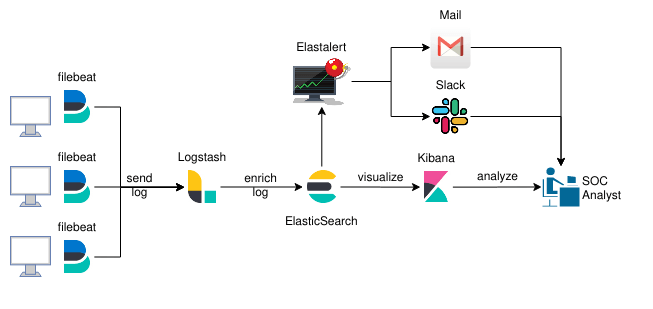
Elastalert notifies you on specific queries for events, but which events does it query? Well, you have to define those. For this purpose we’ll use the SIGMA rules project (https://github.com/Neo23x0/sigma). Sigma is a standard rule format which allows you to define queries which can be converted to multiple formats such as Kibana’s KQL, Splunk, Arcsight, Qualys and of course, Elastalert (amongst others). To quote it’s creator, Florian Roth
Sigma is for log files what Snort is for network traffic and YARA is for files.
After cloning the repository, you can use the included python script sigma2elastalert.py by David Routin to convert the rules to elastalert format.
Now you have an architecture which can be OS independent, and with community open source rules for detecting malicious events. But what about issues tracking? Well, neither Slack nor Gmail are great for that. Luckily, you can integrate Jira with Elastalert to automatically create an follow up on issues you might find. You have a step by step implementation here: https://qbox.io/blog/jira-alerting-elasticsearch-elastalert-tutorial
Let’s update the diagram with our new additions.
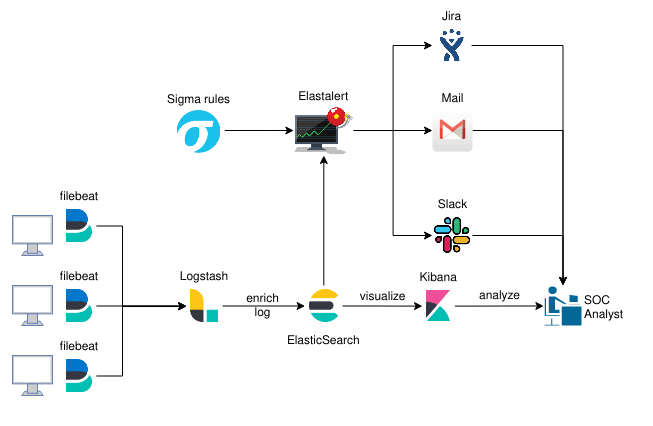
Now we have all the basic needs covered, we can start optimizing our implementation. The solution we have put together so far is a stripped down version of the HELK platform, created by Roberto Rodriguez (https://ift.tt/2FiS46R). For those of you unaware of it, go look it up, its awesome. It covers not only what we’ve done so far, but it also has distributed processing and machine learning features achieved with Apache Spark, Hadoop, GraphFrames and Jupiter Notebooks. We didn’t actually need these features, but you use case might vary.
The third iteration of our architecture does have some issues though. While it does allow us to achieve great granularity when searching for certain events, this comes at the cost of performance. Non relational databases such as ElasticSearch are really fast, but remember one of our first requirements: logging for auditory purposes, and monitoring of commands. Now, let’s do some paper math. You have about 20K servers and a low level audit policy which logs basically every execve syscall ran. You’ve seen on my first write-up how verbose auditd output can get, and even assuming that you strip most of the output down, and keep only the time and the invoked command, thats a lot of info to be querying. The sigma rules repository has about 350 rules. Lets say that you monitor for about 200 malicious commands/strings (between Unix and Windows rules) and that you have about 100 other custom rules defined, specifically for your platform. That’s 650 rules total.
Assuming that each of your servers logs a single syscall every 10 seconds (and thats being generous), you’ll have 650×20000/10= 1.3 million queries per minute.
Of course, this is not 100% accurate, since you have several things that might optimize your lookup times, such as cached queries, but still, that rough number was way out of our infrastructure budget. It also has the disadvantage of delayed notifications. You can increase the query interval, and reduce the load, but you’ll be notified later. That’s the tradeoff. We’re looking for real time alerts. We needed to find another alternative.
Enter Wazuh. Wazuh is an open source host intrusion detection system (HIDS) which can lighten your processing load (https://wazuh.com/). Wazuh can be implemented in several ways, but the most frequent one is having a Wazuh Agent in each of the nodes, and then several Wazuh Managers receiving events. Each Wazuh Agent monitors for several events on the host its installed in, but in can also act as a log forwarder, replacing filebeat. It forwards information about the host to each agent, which will process that information and only forward the alerts that you want to your SIEM.
Wazuh managers can support multiple connections, and help reduce about 80% of the processing of information. This is due to its rules processor, which utilizes specific decoders written in C. This decoder parses the fields for the alerts in a really fast manner, and then matches each rule in a tree-like structure (https://documentation.wazuh.com/3.7/user-manual/ruleset/ruleset-xml-syntax/rules.html).
Wazuh works by defining rules which match on specific events, so you might have something like this (do not use these rules, these have been modified for ilustrative purposes):
Rule 1: detects grouped ssh messages
<rule id="1" level="0" noalert="1">
<decoded_as>sshd</decoded_as>
<description>SSHD messages grouped.</description>
</rule>
Rule 2: detects a failed login
<rule id="2" level="5">
<if_sid>1</if_sid>
<match>illegal user|invalid user</match>
<description>sshd: Attempt to login using a non-existent user</description>
</rule>
Rule 3: detects multiple rules 2 within a defined time period (bruteforce)
<rule id="3" level="10" frequency="8" timeframe="120" ignore="60">
<if_matched_sid>2</if_matched_sid>
<description>sshd: brute force trying to get access to the system.</description>
<same_source_ip />
</rule>
This tree-like structure of rules has two main issues:
- It can get difficult to maintain very quick. Some rules might match first with other rules you don’t expect, or you can end up having spaghetti code if you‘re not planning ahead.
- The granularity level is determined by the rule pre processor. Sure, you can do regex matching, but that doesn’t easily allow you to correlate different matched rules.
Lucky for us, with Wazuh we’re not looking for granularity or detailed events. We’re looking for speed. This means that you can use:
- Wazuh to match the most simple rules in a really fast way (think basic things like string matching for malicious commands, unauthorized logins or ransomware encryption alerts)
- Elastalert with sigma rules for specific use cases which don’t need real time notifications (such as a specific malware group detection rules which can be queried every 5 minutes).
Combining Elastalert and Wazuh you can balance the processing load and have the best of both worlds.
Now our architecture will look something like this:
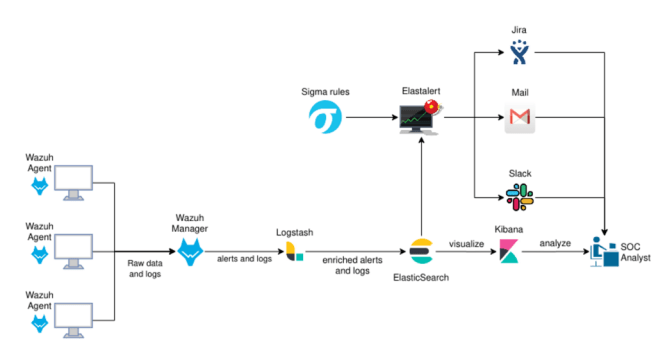
Our final architecture achieves al the objectives that we initially intended. However, it does have the downside of being twice as difficult to maintain, since you now have to tune and monitor two different rulesets, one quick and fast for Wazuh, and one slow but more detailed for Elastalert.
Some last considerations that you need to have (this can be considered more as general architecture rules):
- Always design contemplating that things will fail. In our case, we ended up using 14 Wazuh managers in 4 different environments (native Windows AD, native Unix, native Cloud and AWS Cloud). 10 for the hosts, and 4 for fail-over (one on each region)
- Balance traffic when receiving connections from the agents. You can use something like Nginx, or even use a DNS balancer, but always distribute connections equally through your managers. If you push a config change that requires a restart, all agents can easily DDOS Managers when not distributed correctly.
- Analize the network overhead. Do not use a manager in US infrastructure to receive connections from agents located on the EU. This will not only increase latency times (particularly if you’re using a VPN), but might also incur in extra costs when dealing with cross AZ AWS traffic.
- Make sure to monitor start and stops of the Wazuh agent service, as well as putting limits in place to the amount of logs a single instance can create to prevent DOS attacks through log spamming.
- Conduct frequent red-team exercises to verify that your alerts are working properly. You can Mitre’s Att&ck framework to map unit tests (https://attack.mitre.org/) as well as something like Red Canary’s Atomic Tests (https://github.com/redcanaryco/atomic-red-team) to automate the process.
- Sigma and Wazuh rules are updated frequently. Make sure to keep them updated.
- Expand your rule set. Don’t rely only on community written rules. Sometimes you’ll find bugs and have to modify them manually. Other times you might want to incorporate rules written in order formats / for other index structures.
There are two great talks by Teymur Kheirhabarov which I can recommend if you want to practice rule translations.
- “Hunting for credential dumping in windows environment”
- “Hunting for lateral movement in windows infrastructure”

We actually ended up translating a lot of the rules on those talks to monitor use cases specific to our company.
As with everything, this architecture will require a lot of tuning to finish, but you’ll have a solid SIEM which will allow you to:
- Monitor thousands of hosts from different environments / OS.
- Receive real time alerts.
- Implement open source rules as well as write your own custom ones
- Automate the detection, tracking and documentation of threats, for security and auditing purposes.
- Not pay for a single license.
And remember, there’s not a perfect SIEM, but rather one that perfectly matches your needs.
Building a SIEM: combining ELK, Wazuh HIDS and Elastalert for optimal performance was originally published in InfoSec Write-ups on Medium, where people are continuing the conversation by highlighting and responding to this story.
