
InfoSec Write-ups – Medium–
On part 1 we briefly explained how we got administrator privileges to almost all BMC devices hosting a native Openstack cloud. In this part we’ll show how we used these to achieve complete compromise.
If you’ve read up on BMC devices, by now you’ll know that they allow you to
- Monitor
- Reboot
- Reinstall
- KVM
the attached devices. This is great and all, but they only simulate physical access to the server, you still need to get inside. Yes, you could DOS them by shutting them down, but we thought that this wasn’t enough, so we kept digging.
One of the most common ways of compromising an equipment having physical address is rebooting it and manipulating the startup in order to come up with a root shell. You can do this in Unix, Mac and Windows as well.
The caveat of this approach is that each server was usually hosting about 2000 virtual hosts each. So we needed to find a server that wasn’t in use. The plan was to shut it down (or only starting it up, if it was already down) and edit the startup to give us root access. After that, we wanted to take a look at the configuration to find any mistakes / useful data that would allow us to compromise other servers as well.
Openstack allows you to query the local infrastructure and request certain parameters. One of these is the state of the instance, which in this local company’s case, was define as the availability of the instance (white / blacklisted to receive traffic) + the running state (up / down).
We needed to find a blacklisted server (the running state didn’t matter). We managed to find one with disk issues which was down. Luckily, we were able to boot, with the difficulty of having certain parts of the filesystem in read only mode.

Once we found it, we logged in with the previously cracked credentials.
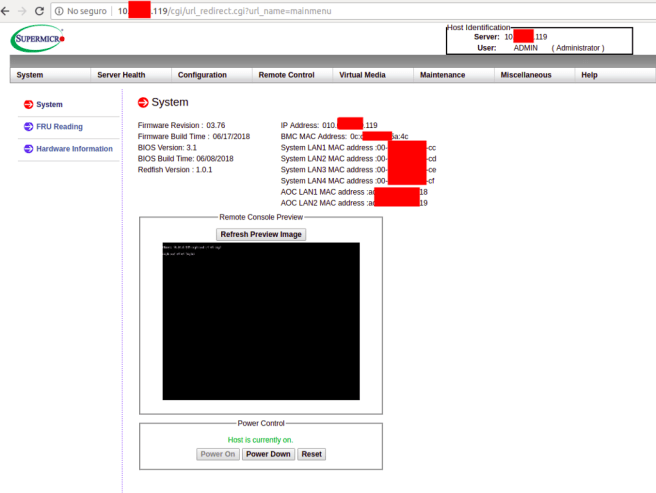
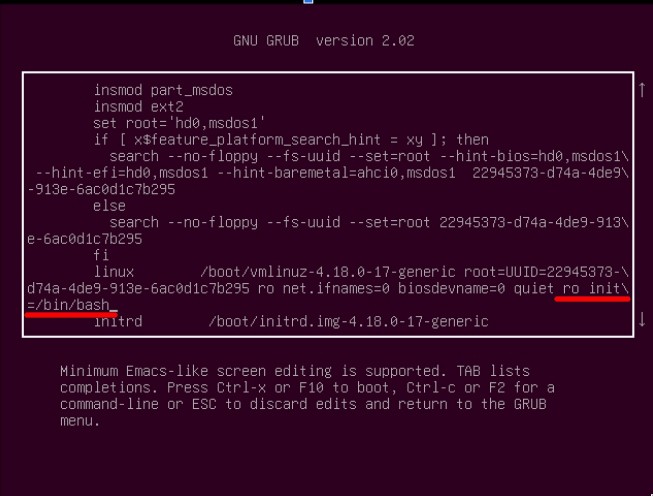
The KVM interface simulates direct connection to the server, through the BMC. When its booting, you need to edit grub’s startup and append
ro init=/bin/bash
to the appropiate line, in order to boot into a root shell (https://wiki.archlinux.org/index.php/Reset_lost_root_password). Usually you would use the read and write flag (rw), but we had to use the read-only one (ro) to prevent any issues with the faulty disk.
After logging in, we listed the network interfaces to verify the server’s connectivity. As you can see, an ifconfig showed over 10 active interfaces.
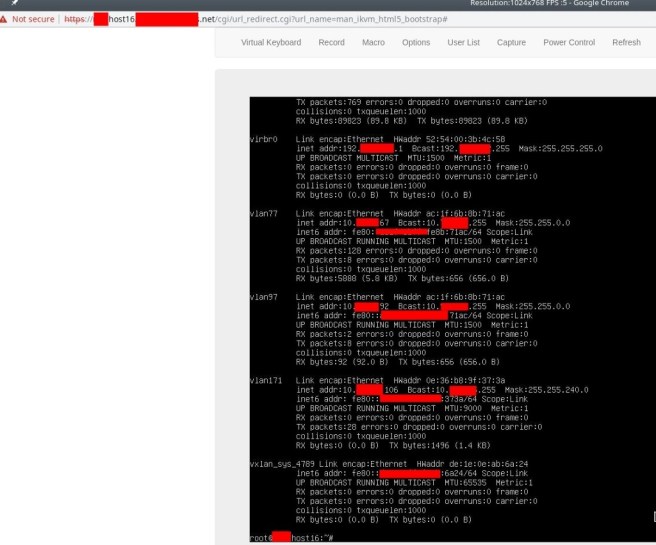
After taking quite some time to analyze what the network layout was, and understand were we were situated, we started analyzing the server.
After a couple of minutes, we struck gold with bash_history (one of the greatest sources of forensic information you can find on a Linux machine)

For those unfamiliar with Openstack’s architecture, Nova is the name of the management database, which holds administrative information for the entire cloud, such as the certificates, quotas, instance names, metadata and a lot of other critical information (https://docs.openstack.org/nova/rocky/cli/nova-manage.html).

After logging in, we verified our administrator access querying MySQL’s grants.

Having checked that, now we can list NovaDB’s internal structure.
When listing instance information, we could see about 34K defined instances. However, about a third of them were inaccessible / not up at any given time. You can get a more reliable number of instances looking at the floating_ips record.
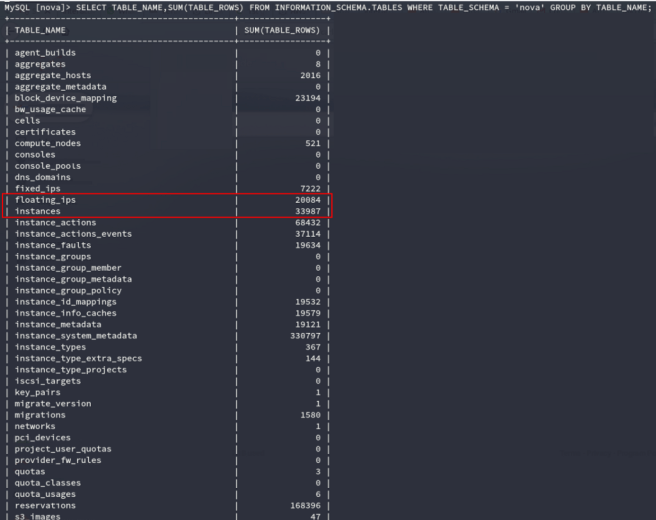
Let me explain why this database finding is so critical.
If you wanted to take the whole company down, you could shut down every virtualization server through the BMC interface, but that would only shut it down until the sysadmins booted everything back up.
You could write write custom malware to infect all servers, but mass deployment through BMC channels is not easy (remember that we needed to start an unused server to edit grubs startup before being able to access it).
With NovaDB access though, you can simply corrupt the database, and the whole cloud environment would stop working. Not only this, but assuming a sysadmin was savvy enough to go look at the DB immediately, it’s much harder to troubleshoot a corrupted database than an inexistent one.
Of course, the sysadmin could realize something’s wrong and simply overwrite everything with the most recent backup right? We’ll, we thought of that too. That’s why we went ahead and compromised the backups.
First we tried querying the master database with something like
SELECT * FROM information_schema.PROCESSLIST AS p WHERE p.COMMAND = 'Binlog Dump';
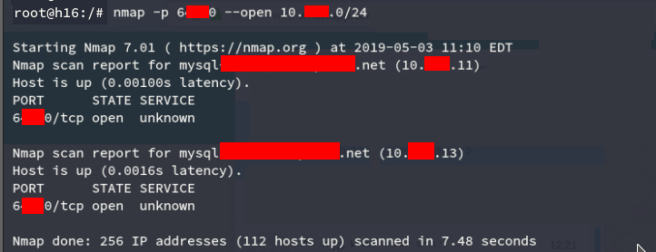
(https://serverfault.com/questions/207640/how-to-find-slaves-ip-address-and-user-name-from-master-server), but they were using a custom solution for the backups, which were done sporadically and not with a master-slave replication schema. So we continued by scanning adjacent subnets, just to find the backup databases running in the same port as the main one.
We checked for credential re-utilization and sure enough, the credentials were the same as the main one.
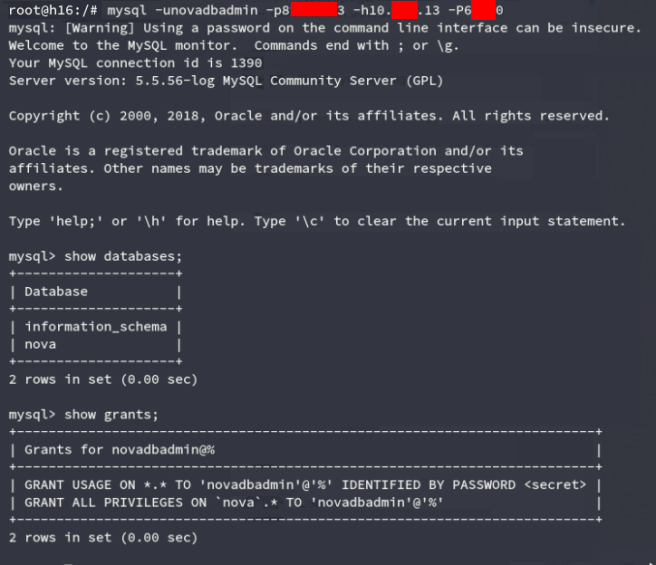
With the backups owned as well, we were able to prove total compromise of the virtualization infrastructure, as well as a way to shutdown operations for good in a few minutes.
I always like to end a write-up / report writing the possible fixes for the issues found. In this case, there were many, such as:
- Credentials re-use
- Missing network segmentation
- Trivial passwords
- Insecure backup structure
- Outdated firmware
One of the critical points which were not easily fixed were the IPMI protocol weaknesses. To quote Dan Farmer’s site:
Note #4. Facebook has put out OpenBMC, an interesting looking implementation that, in theory, may be placed on BMCs. Problematically most vendors (HP, Dell, IBM, etc.) won’t let you install firmware that isn’t signed by them… so you’re out of luck. Plus, the low-level drivers and so on… who knows. I couldn’t get it to build, myself, but let’s remain hopeful. If anyone knows of (publicly available) hardware that this will actually run on, drop me a line.
So the most comprehensive remediation would be placing BMC enabled servers on a different network segment, with a restricted and monitored access IP whitelist. This is what this company ended up doing.
I hope this was educational, we certainly had a lot of fun researching these topics and doing this assessment!
How a badly configured DB allowed us to own an entire cloud of over 25K hosts (part 2/2) was originally published in InfoSec Write-ups on Medium, where people are continuing the conversation by highlighting and responding to this story.
